Двоичный код. Виды и длина двоичного кода
Все символы и буквы могут быть закодированы при помощи восьми двоичных бит. Наиболее распространенными таблицами представления букв в двоичном коде являются ASCII и ANSI, их можно использовать для записи текстов в микропроцессорах. В таблицах ASCII и ANSI первые 128 символов совпадают. В этой части таблицы содержатся коды цифр, знаков препинания, латинские буквы верхнего и нижнего регистров и управляющие символы. Национальные расширения символьных таблиц и символы псевдографики содержатся в последних 128 кодах этих таблиц, поэтому русские тексты в операционных системах DOS и WINDOWS не совпадают.
При первом знакомстве с компьютерами и микропроцессорами может возникнуть вопрос — "как преобразовать текст в двоичный код?" Однако это преобразование является наиболее простым действием! Для этого нужно воспользоваться любым текстовым редактором. В том числе подойдет и простейшая программа notepad, входящая в состав операционной системы Windows. Подобные же редакторы присутствуют во всех средах программирования для языков, таких как СИ, Паскаль или Ява. Следует отметить, что наиболее распространенный текстовый редактор Word для простого преобразования текста в двоичный код не подходит. Этот тестовый редактор вводит огромное количество дополнительной информации, такой как цвет букв, наклон, подчеркивание, язык, на котором написана конкретная фраза, шрифт.
Следует отметить, что на самом деле комбинация нулей и единиц, при помощи которых кодируется текстовая информация двоичным кодом не является, т.к. биты в этом коде не подчиняются законам . Однако в Интернете поисковая фраза "представление букв в двоичном коде" является самой распространенной. В таблице 1 приведено соответствие двоичных кодов буквам латинского алфавита. Для краткости записи в этой таблице последовательность нулей и единиц представлена в десятичном и шестнадцатеричном кодах.
Таблица 1 Таблица представления латинских букв в двоичном коде (ASCII)
| Десятичный код | Шестнадцатеричный код | Отображаемый символ | Значение |
|---|---|---|---|
| 0 | 00 | NUL | |
| 1 | 01 | ☺ | (слово управления дисплеем) |
| 2 | 02 | ☻ | (Первое передаваемое слово) |
| 3 | 03 | ETX (Последнее слово передачи) | |
| 4 | 04 | ♦ | EOT (конец передачи) |
| 5 | 05 | ♣ | ENQ (инициализация) |
| 6 | 06 | ♠ | ACK (подтверждение приема) |
| 7 | 07 | BEL | |
| 8 | 08 | ◘ | BS |
| 9 | 09 | ○ | HT (горизонтальная табуляция |
| 10 | 0A | ◙ | LF (перевод строки) |
| 11 | 0B | ♂ | VT (вертикальная табуляция) |
| 12 | 0С | ♀ | FF (следующая страница) |
| 13 | 0D | ♪ | CR (возврат каретки) |
| 14 | 0E | ♫ | SO (двойная ширина) |
| 15 | 0F | ☼ | SI (уплотненная печать) |
| 16 | 10 | DLE | |
| 17 | 11 | ◄ | DC1 |
| 18 | 12 | ↕ | DC2 (отмена уплотненной печати) |
| 19 | 13 | ‼ | DC3 (готовность) |
| 20 | 14 | ¶ | DC4 (отмена двойной ширины) |
| 21 | 15 | § | NAC (неподтверждение приема) |
| 22 | 16 | ▬ | SYN |
| 23 | 17 | ↨ | ETB |
| 24 | 18 | CAN | |
| 25 | 19 | ↓ | EM |
| 26 | 1A | → | SUB |
| 27 | 1B | ← | ESC (начало управл. послед.) |
| 28 | 1C | ∟ | FS |
| 29 | 1D | ↔ | GS |
| 30 | 1E | ▲ | RS |
| 31 | 1F | ▼ | US |
| 32 | 20 | Пробел | |
| 33 | 21 | ! | Восклицательный знак |
| 34 | 22 | « | Угловая скобка |
| 35 | 23 | # | Знак номера |
| 36 | 24 | $ | Знак денежной единицы (доллар) |
| 37 | 25 | % | Знак процента |
| 38 | 26 | & | Амперсанд |
| 39 | 27 | " | Апостроф |
| 40 | 28 | ( | Открывающая скобка |
| 41 | 29 | ) | Закрывающая скобка |
| 42 | 2A | * | Звездочка |
| 43 | 2B | + | Знак плюс |
| 44 | 2C | , | Запятая |
| 45 | 2D | - | Знак минус |
| 46 | 2E | . | Точка |
| 47 | 2F | / | Дробная черта |
| 48 | 30 | 0 | Цифра ноль |
| 49 | 31 | 1 | Цифра один |
| 50 | 32 | 2 | Цифра два |
| 51 | 33 | 3 | Цифра три |
| 52 | 34 | 4 | Цифра четыре |
| 53 | 35 | 5 | Цифра пять |
| 54 | 36 | 6 | Цифра шесть |
| 55 | 37 | 7 | Цифра семь |
| 56 | 38 | 8 | Цифра восемь |
| 57 | 39 | 9 | Цифра девять |
| 58 | 3A | : | Двоеточие |
| 59 | 3B | ; | Точка с запятой |
| 60 | 3C | < | Знак меньше |
| 61 | 3D | = | Знак равно |
| 62 | 3E | > | Знак больше |
| 63 | 3F | ? | Знак вопрос |
| 64 | 40 | @ | Коммерческое эт |
| 65 | 41 | A | Прописная латинская буква А |
| 66 | 42 | B | Прописная латинская буква B |
| 67 | 43 | C | Прописная латинская буква C |
| 68 | 44 | D | Прописная латинская буква D |
| 69 | 45 | E | Прописная латинская буква E |
| 70 | 46 | F | Прописная латинская буква F |
| 71 | 47 | G | Прописная латинская буква G |
| 72 | 48 | H | Прописная латинская буква H |
| 73 | 49 | I | Прописная латинская буква I |
| 74 | 4A | J | Прописная латинская буква J |
| 75 | 4B | K | Прописная латинская буква K |
| 76 | 4C | L | Прописная латинская буква L |
| 77 | 4D | M | Прописная латинская буква |
| 78 | 4E | N | Прописная латинская буква N |
| 79 | 4F | O | Прописная латинская буква O |
| 80 | 50 | P | Прописная латинская буква P |
| 81 | 51 | Q | Прописная латинская буква |
| 82 | 52 | R | Прописная латинская буква R |
| 83 | 53 | S | Прописная латинская буква S |
| 84 | 54 | T | Прописная латинская буква T |
| 85 | 55 | U | Прописная латинская буква U |
| 86 | 56 | V | Прописная латинская буква V |
| 87 | 57 | W | Прописная латинская буква W |
| 88 | 58 | X | Прописная латинская буква X |
| 89 | 59 | Y | Прописная латинская буква Y |
| 90 | 5A | Z | Прописная латинская буква Z |
| 91 | 5B | [ | Открывающая квадратная скобка |
| 92 | 5C | \ | Обратная черта |
| 93 | 5D | ] | Закрывающая квадратная скобка |
| 94 | 5E | ^ | "Крышечка" |
| 95 | 5 | _ | Символ подчеркивания |
| 96 | 60 | ` | Апостроф |
| 97 | 61 | a | Строчная латинская буква a |
| 98 | 62 | b | Строчная латинская буква b |
| 99 | 63 | c | Строчная латинская буква c |
| 100 | 64 | d | Строчная латинская буква d |
| 101 | 65 | e | Строчная латинская буква e |
| 102 | 66 | f | Строчная латинская буква f |
| 103 | 67 | g | Строчная латинская буква g |
| 104 | 68 | h | Строчная латинская буква h |
| 105 | 69 | i | Строчная латинская буква i |
| 106 | 6A | j | Строчная латинская буква j |
| 107 | 6B | k | Строчная латинская буква k |
| 108 | 6C | l | Строчная латинская буква l |
| 109 | 6D | m | Строчная латинская буква m |
| 110 | 6E | n | Строчная латинская буква n |
| 111 | 6F | o | Строчная латинская буква o |
| 112 | 70 | p | Строчная латинская буква p |
| 113 | 71 | q | Строчная латинская буква q |
| 114 | 72 | r | Строчная латинская буква r |
| 115 | 73 | s | Строчная латинская буква s |
| 116 | 74 | t | Строчная латинская буква t |
| 117 | 75 | u | Строчная латинская буква u |
| 118 | 76 | v | Строчная латинская буква v |
| 119 | 77 | w | Строчная латинская буква w |
| 120 | 78 | x | Строчная латинская буква x |
| 121 | 79 | y | Строчная латинская буква y |
| 122 | 7A | z | Строчная латинская буква z |
| 123 | 7B | { | Открывающая фигурная скобка |
| 124 | 7С | | | Вертикальная черта |
| 125 | 7D | } | Закрывающая фигурная скобка |
| 126 | 7E | ~ | Тильда |
| 127 | 7F | ⌂ |
В классическом варианте таблицы символов ASCII нет русских букв и она состоит из 7 бит. Однако в дальнейшем эта таблица была расширена до 8 бит и в старших 128 строках появились русские буквы в двоичном коде и символы псевдографики. В общем случае во второй части размещены национальные алфавиты разных стран и русские буквы там просто один из возможных наборов (855) там может быть французская (863), немецкая (1141) или греческая (737) таблица. В таблице 2 приведен пример представления русских букв в двоичном коде.
Таблица 2. Таблица представления русских букв в двоичном коде (ASCII)
| Десятичный код | Шестнадцатеричный код | Отображаемый символ | Значение |
|---|---|---|---|
| 128 | 80 | А | Прописная русская буква А |
| 129 | 81 | Б | Прописная русская буква Б |
| 130 | 82 | В | Прописная русская буква В |
| 131 | 83 | Г | Прописная русская буква Г |
| 132 | 84 | Д | Прописная русская буква Д |
| 133 | 85 | Е | Прописная русская буква Е |
| 134 | 86 | Ж | Прописная русская буква Ж |
| 135 | 87 | З | Прописная русская буква З |
| 136 | 88 | И | Прописная русская буква И |
| 137 | 89 | Й | Прописная русская буква Й |
| 138 | 8A | К | Прописная русская буква К |
| 139 | 8B | Л | Прописная русская буква Л |
| 140 | 8C | М | Прописная русская буква М |
| 141 | 8D | Н | Прописная русская буква Н |
| 142 | 8E | О | Прописная русская буква О |
| 143 | 8F | П | Прописная русская буква П |
| 144 | 90 | Р | Прописная русская буква Р |
| 145 | 91 | С | Прописная русская буква С |
| 146 | 92 | Т | Прописная русская буква Т |
| 147 | 93 | У | Прописная русская буква У |
| 148 | 94 | Ф | Прописная русская буква Ф |
| 149 | 95 | Х | Прописная русская буква Х |
| 150 | 96 | Ц | Прописная русская буква Ц |
| 151 | 97 | Ч | Прописная русская буква Ч |
| 152 | 98 | Ш | Прописная русская буква Ш |
| 153 | 99 | Щ | Прописная русская буква Щ |
| 154 | 9A | Ъ | Прописная русская буква Ъ |
| 155 | 9B | Ы | Прописная русская буква Ы |
| 156 | 9C | Ь | Прописная русская буква Ь |
| 157 | 9D | Э | Прописная русская буква Э |
| 158 | 9E | Ю | Прописная русская буква Ю |
| 159 | 9F | Я | Прописная русская буква Я |
| 160 | A0 | а | Строчная русская буква а |
| 161 | A1 | б | Строчная русская буква б |
| 162 | A2 | в | Строчная русская буква в |
| 163 | A3 | г | Строчная русская буква г |
| 164 | A4 | д | Строчная русская буква д |
| 165 | A5 | е | Строчная русская буква е |
| 166 | A6 | ж | Строчная русская буква ж |
| 167 | A7 | з | Строчная русская буква з |
| 168 | A8 | и | Строчная русская буква и |
| 169 | A9 | й | Строчная русская буква й |
| 170 | AA | к | Строчная русская буква к |
| 171 | AB | л | Строчная русская буква л |
| 172 | AC | м | Строчная русская буква м |
| 173 | AD | н | Строчная русская буква н |
| 174 | AE | о | Строчная русская буква о |
| 175 | AF | п | Строчная русская буква п |
| 176 | B0 | ░ | |
| 177 | B1 | ▒ | |
| 178 | B2 | ▓ | |
| 179 | B3 | │ | Символ псевдографики |
| 180 | B4 | ┤ | Символ псевдографики |
| 181 | B5 | ╡ | Символ псевдографики |
| 182 | B6 | ╢ | Символ псевдографики |
| 183 | B7 | ╖ | Символ псевдографики |
| 184 | B8 | ╕ | Символ псевдографики |
| 185 | B9 | ╣ | Символ псевдографики |
| 186 | BA | ║ | Символ псевдографики |
| 187 | BB | ╗ | Символ псевдографики |
| 188 | BC | ╝ | Символ псевдографики |
| 189 | BD | ╜ | Символ псевдографики |
| 190 | BE | ╛ | Символ псевдографики |
| 191 | BF | ┐ | Символ псевдографики |
| 192 | C0 | └ | Символ псевдографики |
| 193 | C1 | ┴ | Символ псевдографики |
| 194 | C2 | ┬ | Символ псевдографики |
| 195 | C3 | ├ | Символ псевдографики |
| 196 | C4 | ─ | Символ псевдографики |
| 197 | C5 | ┼ | Символ псевдографики |
| 198 | C6 | ╞ | Символ псевдографики |
| 199 | C7 | ╟ | Символ псевдографики |
| 200 | C8 | ╚ | Символ псевдографики |
| 201 | C9 | ╔ | Символ псевдографики |
| 202 | CA | ╩ | Символ псевдографики |
| 203 | CB | ╦ | Символ псевдографики |
| 204 | CC | ╠ | Символ псевдографики |
| 205 | CD | ═ | Символ псевдографики |
| 206 | CE | ╬ | Символ псевдографики |
| 207 | CF | ╧ | Символ псевдографики |
| 208 | D0 | ╨ | Символ псевдографики |
| 209 | D1 | ╤ | Символ псевдографики |
| 210 | D2 | ╥ | Символ псевдографики |
| 211 | D3 | ╙ | Символ псевдографики |
| 212 | D4 | ╘ | Символ псевдографики |
| 213 | D5 | ╒ | Символ псевдографики |
| 214 | D6 | ╓ | Символ псевдографики |
| 215 | D7 | ╫ | Символ псевдографики |
| 216 | D8 | ╪ | Символ псевдографики |
| 217 | D9 | ┘ | Символ псевдографики |
| 218 | DA | ┌ | Символ псевдографики |
| 219 | DB | █ | |
| 220 | DC | ▄ | |
| 221 | DD | ▌ | |
| 222 | DE | ▐ | |
| 223 | DF | ▀ | |
| 224 | E0 | р | Строчная русская буква р |
| 225 | E1 | с | Строчная русская буква с |
| 226 | E2 | т | Строчная русская буква т |
| 227 | E3 | у | Строчная русская буква у |
| 228 | E4 | ф | Строчная русская буква ф |
| 229 | E5 | х | Строчная русская буква х |
| 230 | E6 | ц | Строчная русская буква ц |
| 231 | E7 | ч | Строчная русская буква ч |
| 232 | E8 | ш | Строчная русская буква ш |
| 233 | E9 | щ | Строчная русская буква щ |
| 234 | EA | ъ | Строчная русская буква ъ |
| 235 | EB | ы | Строчная русская буква ы |
| 236 | EC | ь | Строчная русская буква ь |
| 237 | ED | э | Строчная русская буква э |
| 238 | EE | ю | Строчная русская буква ю |
| 239 | EF | я | Строчная русская буква я |
| 240 | F0 | Ё | Прописная русская буква Ё |
| 241 | F1 | ё | Строчная русская буква ё |
| 242 | F2 | Є | |
| 243 | F3 | є | |
| 244 | F4 | Ї | |
| 245 | F5 | Ї | |
| 246 | F6 | Ў | |
| 247 | F7 | ў | |
| 248 | F8 | ° | Знак градуса |
| 249 | F9 | ∙ | Знак умножения (точка) |
| 250 | FA | · | |
| 251 | FB | √ | Радикал (взятие корня) |
| 252 | FC | № | Знак номера |
| 253 | FD | ¤ | Знак денежной единицы (рубль) |
| 254 | FE | ■ | |
| 255 | FF |
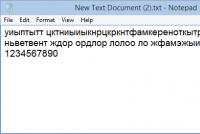
При записи текстов кроме двоичных кодов, непосредственно отображающих буквы, применяются коды, обозначающие переход на новую строку и возврат курсора (возврат каретки) на нулевую позицию строки. Эти символы обычно применяются вместе. Их двоичные коды соответствуют десятичным числам — 10 (0A) и 13 (0D). В качестве примера ниже приведен участок текста данной страницы (дамп памяти). На этом участке записан ее первый абзац. Для отображения информации в дампе памяти применен следующий формат:
- в первой колонке записан двоичный адрес первого байта строки
- в следующи шестнадцати колонках записаны байты, содержащиеся в текстовом файле. Для более удобного определения номера байта после восьмой колонки проведена вертикальная линия. Байты, для краткости записи, представлены в шестнадцатеричном коде.
- в последней колонке эти же байты представлены в виде отображаемых буквенных символов
В приведенном примере видно, что первая строка текста занимает 80 байт. Первый байт 82 соответствует букве "В". Второй байт E1 соответствует букве "с". Третий байт A5 соответствует букве "е". Следующий байт 20 отображает пустой промежуток между словами (пробел) " ". 81 и 82 байты содержат символы возврата каретки и перевода строки 0D 0A. Эти символы мы находим по двоичному адресу 00000050: Следующая строка исходного текста не кратна 16 (ее длина равна 76 буквам), поэтому для того, чтобы найти ее конец потребуется сначала найти строку 000000E0: и от нее отсчитать девять колонок. Там снова записаны байты возврата каретки и перевода строки 0D 0A. Остальной текст анализируется точно таким же образом.
Дата последнего обновления файла 04.12.2018
Литература:
Вместе со статьей "Запись текстов двоичным кодом" читают:
Представление двоичных чисел в памяти компьютера или
микроконтроллера
http://сайт/proc/IntCod.php
Иногда бывает удобно хранить числа в памяти процессора в десятичном
виде
http://сайт/proc/DecCod.php
Стандартные форматы чисел
с плавающей запятой для компьютеров и микроконтроллеров
http://сайт/proc/float/
В настоящее время и в технике и в быту широко используются как
позиционные, так и непозиционные системы счисления.
.php
Двоичный переводчик - это инструмент для перевода двоичного кода в текст для чтения или печати. Вы можете перевести двоичный файл на английский, используя два метода; ASCII и Unicode.
Двоичная система счисления
Система двоичного декодера основана на числе 2 (основание). Он состоит только из двух чисел как системы счисления base-2: 0 и 1.
Хотя бинарная система применялась в различных целях в древнем Египте, Китае и Индии, она стала языком электроники и компьютеров современного мира. Это наиболее эффективная система для обнаружения выключенного (0) и включенного (1) состояния электрического сигнала. Это также основа двоичного кода в текст, который используется на компьютерах для составления данных. Даже цифровой текст, который вы сейчас читаете, состоит из двоичных чисел. Но вы можете прочитать этот текст, потому что мы расшифровали двоичный код перевод файл, используя двоичный код слова.
Что такое ASCII?
ASCII - это стандарт кодирования символов для электронной связи, сокращенный от Американского стандартного кода для обмена информацией. В компьютерах, телекоммуникационном оборудовании и других устройствах коды ASCII представляют текст. Хотя поддерживается много дополнительных символов, большинство современных схем кодирования символов основаны на ASCII.
ASCII - это традиционное название для системы кодирования; Управление по присвоению номеров в Интернете (IANA) предпочитает обновленное имя США-ASCII, которое поясняет, что эта система была разработана в США и основана на преимущественно используемых типографских символах. ASCII является одним из основных моментов IEEE.
Бинарный в ASCII
Первоначально основанный на английском алфавите, ASCII кодирует 128 указанных семибитных целочисленных символов. Можно печатать 95 кодированных символов, включая цифры от 0 до 9, строчные буквы от a до z, прописные буквы от A до Z и символы пунктуации. Кроме того, 33 непечатных контрольных кода, полученных с помощью машин Teletype, были включены в исходную спецификацию ASCII; большинство из них в настоящее время устарели, хотя некоторые все еще широко используются, такие как возврат каретки, перевод строки и коды табуляции.
Например, двоичное число 1101001 = шестнадцатеричное 69 (i - девятая буква) = десятичное число 105 будет представлять строчный I в кодировке ASCII.
Использование ASCII
Как уже упоминалось выше, используя ASCII, вы можете перевести компьютерный текст в человеческий текст. Проще говоря, это переводчик с бинарного на английский. Все компьютеры получают сообщения в двоичном, 0 и 1 серии. Тем не менее, так же, как английский и испанский могут использовать один и тот же алфавит, но для многих похожих слов у них совершенно разные слова, у компьютеров также есть своя языковая версия. ASCII используется как метод, который позволяет всем компьютерам обмениваться документами и файлами на одном языке.
ASCII важен, потому что при разработке компьютерам был дан общий язык.
В 1963 году ASCII впервые был коммерчески использован в качестве семибитного кода телепринтера для сети TWX (Teletype Writer eXchange) American Telephone & Telegraph. Первоначально TWX использовал предыдущую пятибитную ITA2, которую также использовала конкурирующая телепринтерная система Telex. Боб Бемер представил такие функции, как последовательность побега. По словам Бемера, его британский коллега Хью МакГрегор Росс помог популяризировать эту работу - «настолько, что код, который стал ASCII, впервые был назван Кодексом Бемера-Росса в Европе». Из-за его обширной работы ASCII, Бемер был назван "отцом ASCII".
До декабря 2007 года, когда кодировка UTF-8 превосходила ее, ASCII была наиболее распространенной кодировкой символов во Всемирной паутине; UTF-8 обратно совместим с ASCII.
UTF-8 (Юникод)
UTF-8 - это кодировка символов, которая может быть такой же компактной, как ASCII, но также может содержать любые символы Юникода (с некоторым увеличением размера файла). UTF - это формат преобразования Unicode. «8» означает представление символа с использованием 8-битных блоков. Количество блоков, которые должен представлять персонаж, варьируется от 1 до 4. Одной из действительно приятных особенностей UTF-8 является то, что он совместим со строками с нулевым символом в конце. При кодировании ни один символ не будет иметь байта nul (0).
Unicode и универсальный набор символов (UCS) ISO / IEC 10646 имеют гораздо более широкий диапазон символов, и их различные формы кодирования начали быстро заменять ISO / IEC 8859 и ASCII во многих ситуациях. Хотя ASCII ограничен 128 символами, Unicode и UCS поддерживают большее количество символов посредством разделения уникальных концепций идентификации (с использованием натуральных чисел, называемых кодовыми точками) и кодирования (до двоичных форматов UTF-8, UTF-16 и UTF-32-битных).).
Разница между ASCII и UTF-8
ASCII был включен как первые 128 символов в набор символов Unicode (1991), поэтому 7-разрядные символы ASCII в обоих наборах имеют одинаковые числовые коды. Это позволяет UTF-8 быть совместимым с 7-битным ASCII, поскольку файл UTF-8 с только символами ASCII идентичен файлу ASCII с той же последовательностью символов. Что еще более важно, прямая совместимость обеспечивается, поскольку программное обеспечение, которое распознает только 7-битные символы ASCII как специальные и не изменяет байты с самым высоким установленным битом (как это часто делается для поддержки 8-битных расширений ASCII, таких как ISO-8859-1), будет сохранить неизмененные данные UTF-8.
Приложения переводчика двоичного кода
Наиболее распространенное применение для этой системы счисления можно увидеть в компьютерных технологиях. В конце концов, основой всего компьютерного языка и программирования является двузначная система счисления, используемая в цифровом кодировании.
Это то, что составляет процесс цифрового кодирования, беря данные и затем изображая их с ограниченными битами информации. Ограниченная информация состоит из нулей и единиц двоичной системы. Изображения на экране вашего компьютера являются примером этого. Для кодирования этих изображений для каждого пикселя используется двоичная строка.
Если на экране используется 16-битный код, каждому пикселю будут даны инструкции, какой цвет отображать на основе того, какие биты равны 0 и 1. В результате получается более 65 000 цветов, представленных 2 ^ 16. В дополнение к этому вы найдете применение двоичной системы счисления в математической ветви, известной как булева алгебра.
Ценности логики и истины относятся к этой области математики. В этом приложении заявлениям присваивается 0 или 1 в зависимости от того, являются ли они истинными или ложными. Вы можете попробовать преобразование двоичного в текстовое, десятичное в двоичное, двоичное в десятичное преобразование, если вы ищете инструмент, который помогает в этом приложении.
Преимущество двоичной системы счисления
Система двоичных чисел полезна для ряда вещей. Например, компьютер щелкает переключателями для добавления чисел. Вы можете стимулировать добавление компьютера, добавляя двоичные числа в систему. В настоящее время есть две основные причины использования этой компьютерной системы счисления. Во-первых, это может обеспечить надежность диапазона безопасности. Вторично и самое главное, это помогает минимизировать необходимые схемы. Это уменьшает необходимое пространство, потребляемую энергию и расходы.
Вы можете кодировать или переводить двоичные сообщения, написанные двоичными числами. Например,
(01101001) (01101100011011110111011001100101) (011110010110111101110101) является декодированным сообщением. Когда вы скопируете и вставите эти цифры в наш бинарный переводчик, вы получите следующий текст на английском языке:
Я люблю тебя
Это означает
(01101001) (01101100011011110111011001100101) (011110010110111101110101) = Я тебя люблю
таблицы
|
двоичный |
шестнадцатеричный |
|
|---|---|---|
Двоичный код - это подача информации путем сочетания символов 0 или 1. Порою бывает очень сложно понять принцип кодирования информации в виде этих двух чисел, однако мы постараемся все подробно разъяснить.
Кстати, на нашем сайте вы можете перевести любой текст в десятичный, шестнадцатеричный, двоичный код воспользовавшись Калькулятором кодов онлайн .
Видя что-то впервые, мы зачастую задаемся логичным вопросом о том, как это работает. Любая новая информация воспринимается нами, как что-то сложное или созданное исключительно для разглядываний издали, однако для людей, желающих узнать подробнее о двоичном коде , открывается незамысловатая истина - бинарный код вовсе не сложный для понимания, как нам кажется. К примеру, английская буква T в двоичной системе приобретет такой вид - 01010100, E - 01000101 и буква X - 01011000. Исходя из этого, понимаем, что английское слово TEXT в виде двоичного кода будет выглядеть таким вот образом: 01010100 01000101 01011000 01010100. Компьютер понимает именно такое изложение символов для данного слова, ну а мы предпочитаем видеть его в изложении букв алфавита.
На сегодняшний день двоичный код активно используется в программировании, поскольку работают вычислительные машины именно благодаря ему. Но программирование не свелось до бесконечного набора нулей и единиц. Поскольку это достаточно трудоемкий процесс, были приняты меры для упрощения понимания между компьютером и человеком. Решением проблемы послужило создание языков программирования (бейсик, си++ и т.п.). В итоге программист пишет программу на языке, который он понимает, а потом программа-компилятор переводит все в машинный код, запуская работу компьютера.
Перевод натурального числа десятичной системы счисления в двоичную систему.
Чтобы перевести числа из десятичной системы счисления в двоичную пользуются "алгоритмом замещения", состоящим из такой последовательности действий:
1. Выбираем нужное число и делим его на 2. Если результат деления получился с остатком, то число двоичного кода будет 1, если остатка нет - 0.
2. Откидывая остаток, если он есть, снова делим число, полученное в результате первого деления, на 2. Устанавливаем число двоичной системы в зависимости от наличия остатка.
3. Продолжаем делить, вычисляя число двоичной системы из остатка, до тех пор, пока не дойдем до числа, которое делить нельзя - 0.
4. В этот момент считается, что двоичный код готов.
Для примера переведем в двоичную систему число 7:
1. 7: 2 = 3.5. Поскольку остаток есть, записываем первым числом двоичного кода 1.
2. 3: 2 = 1.5. Повторяем процедуру с выбором числа кода между 1 и 0 в зависимости от остатка.
3. 1: 2 = 0.5. Снова выбираем 1 по тому же принципу.
4. В результате получаем, переведенный из десятичной системы счисления в двоичную, код - 111.
Таким образом можно переводить бесконечное множество чисел. Теперь попробуем сделать наоборот - перевести число из двоичной в десятичную.
Перевод числа двоичной системы в десятичную.
Для этого нам нужно пронумеровать наше двоичное число 111 с конца, начиная нулем. Для 111 это 1^2 1^1 1^0. Исходя из этого, номер для числа послужит его степенем. Далее выполняем действия по формуле: (x * 2^y) + (x * 2^y) + (x * 2^y), где x - порядковое число двоичного кода, а y - степень этого числа. Подставляем наше двоичное число под эту формулу и считаем результат. Получаем: (1 * 2^2) + (1 * 2^1) + (1 * 2^0) = 4 + 2 + 1 = 7.
Немного из истории двоичной системы счисления.
Принято считать, что впервые двоичную систему предложил Готфрид Вильгельм Лейбниц, который считал систему полезной в сложных математических вычислениях и науке. Но по неким данным, до его предложения о двоичной системе счисления, в Китае появилась настенная надпись, которая расшифровывалась при использовании двоичного кода . На надписи были изображены длинные и короткие палочки. Предполагая, что длинная это 1, а короткая палочка - 0, есть доля вероятности, что в Китае идея двоичного кода существовала многим ранее его официального открытия. Расшифровка кода определила там только простое натуральное число, однако это факт, который им и остается.
Термин «бинарный» по смыслу – состоящий из двух частей, компонентов. Таким образом бинарные коды это коды которые состоят только из двух символьных состояний например черный или белый, светлый или темный, проводник или изолятор. Бинарный код в цифровой технике это способ представления данных (чисел, слов и других) в виде комбинации двух знаков, которые можно обозначить как 0 и 1. Знаки или единицы БК называют битами. Одним из обоснований применения БК является простота и надежность накопления информации в каком-либо носителе в виде комбинации всего двух его физических состояний, например в виде изменения или постоянства светового потока при считывании с оптического кодового диска.
Существуют различные возможности кодирования информации.
Двоичный код
В цифровой технике способ представления данных (чисел, слов и других) в виде комбинации двух знаков, которые можно обозначить как 0 и 1. Знаки или единицы ДК называют битами.
Одним из обоснований применения ДК является простота и надежность накопления информации в каком-либо носителе в виде комбинации всего двух его физических состояний, например в виде изменения или постоянства магнитного потока в данной ячейке носителя магнитной записи.
Наибольшее число, которое может быть выражено двоичным кодом, зависит от количества используемых разрядов, т.е. от количества битов в комбинации, выражающей число. Например, для выражения числовых значений от 0 до 7 достаточно иметь 3-разрядный или 3-битовый код:
| числовое значение | двоичный код |
| 0 | 000 |
| 1 | 001 |
| 2 | 010 |
| 3 | 011 |
| 4 | 100 |
| 5 | 101 |
| 6 | 110 |
| 7 | 111 |
Отсюда видно, что для числа больше 7 при 3-разрядном коде уже нет кодовых комбинаций из 0 и 1.
Переходя от чисел к физическим величинам, сформулируем вышеприведенное утверждение в более общем виде: наибольшее количество значений m какой-либо величины (температуры, напряжения, тока и др.), которое может быть выражено двоичным кодом, зависит от числа используемых разрядов n как m=2n. Если n=3, как в рассмотренном примере, то получим 8 значений, включая ведущий 0.
Двоичный код является многошаговым кодом. Это означает, что при переходе с одного положения (значения) в другое могут изменятся несколько бит одновременно. Например число 3 в двоичном коде = 011. Число же 4 в двоичном коде = 100. Соответственно при переходе от 3 к 4 меняют свое состояние на противоположное все 3 бита одновременно. Считывание такого кода с кодового диска привело бы к тому, что из-за неизбежных отклонений (толеранцев) при производстве кодового диска изменение информации от каждой из дорожек в отдельности никогда не произойдет одновременно. Это в свою очередь привело бы к тому, что при переходе от одного числа к другому кратковременно будет выдана неверная информация. Так при вышеупомянутом переходе от числа 3 к числу 4 очень вероятна кратковременная выдача числа 7 когда, например, старший бит во время перехода поменял свое значение немного раньше чем остальные. Чтобы избежать этого, применяется так называемый одношаговый код, например так называемый Грей-код.
Код Грея
Грей-код является так называемым одношаговым кодом, т.е. при переходе от одного числа к другому всегда меняется лишь какой-то один из всех бит информации. Погрешность при считывании информации с механического кодового диска при переходе от одного числа к другому приведет лишь к тому, что переход от одного положения к другом будет лишь несколько смещен по времени, однако выдача совершенно неверного значения углового положения при переходе от одного положения к другому полностью исключается.
Преимуществом Грей-кода является также его способность зеркального отображения информации. Так инвертируя старший бит можно простым образом менять направление счета и таким образом подбирать к фактическому (физическому) направлению вращения оси. Изменение направления счета таким образом может легко изменяться управляя так называемым входом ” Complement “. Выдаваемое значение может таким образом быть возврастающим или спадающим при одном и том же физическом направлении вращения оси.
Поскольку информация выраженая в Грей-коде имеет чисто кодированный характер не несущей реальной числовой информации должен он перед дальнейшей обработкой сперва преобразован в стандартный бинарный код. Осуществляется это при помощи преобразователя кода (декодера Грей-Бинар) который к счастью легко реализируется с помощью цепи из логических элементов «исключающее или» (XOR) как програмным так и аппаратным способом.
Соответствие десятичных чисел в диапазоне от 0 до 15 двоичному коду и коду Грея
| Двоичное кодирование | Кодирование по методу Грея |
||||
| Десятичный код |
Двоичное значение | Шестнадц. значение | Десятичный код | Двоичное значение | Шестнадц. значение |
| 0 | 0000 | 0h | 0 | 0000 | 0h |
| 1 | 0001 | 1h | 1 | 0001 | 1h |
| 2 | 0010 | 2h | 3 | 0011 | 3h |
| 3 | 0011 | 3h | 2 | 0010 | 2h |
| 4 | 0100 | 4h | 6 | 0110 | 6h |
| 5 | 0101 | 5h | 7 | 0111 | 7h |
| 6 | 0110 | 6h | 5 | 0101 | 5h |
| 7 | 0111 | 7h | 4 | 0100 | 4h |
| 8 | 1000 | 8h | 12 | 1100 | Ch |
| 9 | 1001 | 9h | 13 | 1101 | Dh |
| 10 | 1010 | Ah | 15 | 1111 | Fh |
| 11 | 1011 | Bh | 14 | 1110 | Eh |
| 12 | 1100 | Ch | 10 | 1010 | Ah |
| 13 | 1101 | Dh | 11 | 1011 | Bh |
| 14 | 1110 | Eh | 9 | 1001 | 9h |
| 15 | 1111 | Fh | 8 | 1000 | 8h |
Преобразование кода Грея в привычный бинарный код можно осуществить используя простую схему с инверторами и логическими элементами “исключающее или” как показано ниже:
Код Gray-Excess
Обычный одношаговый Грей-код подходит для разрешений, которые могут быть представлены в виде числа возведенного в степень 2. В случаях где надо реализовать другие разрешения из обычного Грей-кода вырезается и используется средний его участок. Таким образом сохраняется «одношаговость» кода. Однако числовой диапазон начинается не с нуля, а смещяется на определенное значение. При обработке информации от генерируемого сигнала отнимается половина разницы между первоначальным и редуцированным разрешением. Такие разрешения как например 360? для выражения угла часто реализируются этим методом. Так 9-ти битный Грей-код равный 512 шагов, урезанный с обеих сторон на 76 шагов будет равен 360°.
08. 06.2018
Блог Дмитрия Вассиярова.
Двоичный код — где и как применяется?
Сегодня я по-особому рад своей встрече с вами, дорогие мои читатели, ведь я чувствую себя учителем, который на самом первом уроке начинает знакомить класс с буквами и цифрами. А поскольку мы живем в мире цифровых технологий, то я расскажу вам, что такое двоичный код, являющийся их основой.

Начнем с терминологии и выясним, что означит двоичный. Для пояснения вернемся к привычному нам исчислению, которое называется «десятичным». То есть, мы используем 10 знаков-цифр, которые дают возможность удобно оперировать различными числами и вести соответствующую запись.
Следуя этой логике, двоичная система предусматривает использование только двух знаков. В нашем случае, это всего лишь «0» (ноль) и «1» единица. И здесь я хочу вас предупредить, что гипотетически на их месте могли бы быть и другие условные обозначения, но именно такие значения, обозначающие отсутствие (0, пусто) и наличие сигнала (1 или «палочка»), помогут нам в дальнейшем уяснить структуру двоичного кода.
Зачем нужен двоичный код?
До появления ЭВМ использовались различные автоматические системы, принцип работы которых основан на получении сигнала. Срабатывает датчик, цепь замыкается и включается определенное устройство. Нет тока в сигнальной цепи – нет и срабатывания. Именно электронные устройства позволили добиться прогресса в обработке информации, представленной наличием или отсутствием напряжения в цепи.

Дальнейшее их усложнение привело к появлению первых процессоров, которые так же выполняли свою работу, обрабатывая уже сигнал, состоящий из импульсов, чередующихся определенным образом. Мы сейчас не будем вникать в программные подробности, но для нас важно следующее: электронные устройства оказались способными различать заданную последовательность поступающих сигналов. Конечно, можно и так описать условную комбинацию: «есть сигнал»; «нет сигнала»; «есть сигнал»; «есть сигнал». Даже можно упростить запись: «есть»; «нет»; «есть»; «есть».
Но намного проще обозначить наличие сигнала единицей «1», а его отсутствие – нулем «0». Тогда мы вместо всего этого сможем использовать простой и лаконичный двоичный код: 1011.
Безусловно, процессорная техника шагнула далеко вперед и сейчас чипы способны воспринимать не просто последовательность сигналов, а целые программы, записанные определенными командами, состоящими из отдельных символов.
Но для их записи используется все тот же двоичный код, состоящий из нулей и единиц, соответствующий наличию или отсутствию сигнала. Есть он, или его нет – без разницы. Для чипа любой из этих вариантов – это единичная частичка информации, которая получила название «бит» (bit — официальная единица измерения).
Условно, символ можно закодировать последовательностью из нескольких знаков. Двумя сигналами (или их отсутствием) можно описать всего четыре варианта: 00; 01;10; 11. Такой способ кодирования называется двухбитным. Но он может быть и:
- Четырехбитным (как в примере на абзац выше 1011) позволяет записать 2^4 = 16 комбинаций-символов;
- Восьмибитным (например: 0101 0011; 0111 0001). Одно время он представлял наибольший интерес для программирования, поскольку охватывал 2^8 = 256 значений. Это давало возможность описать все десятичные цифры, латинский алфавит и специальные знаки;
- Шестнадцатибитным (1100 1001 0110 1010) и выше. Но записи с такой длинной – это уже для современных более сложных задач. Современные процессоры используют 32-х и 64-х битную архитектуру;
Скажу честно, единой официальной версии нет, то так сложилось, что именно комбинация из восьми знаков стала стандартной мерой хранящейся информации, именуемой «байт». Таковая могла применяться даже к одной букве, записанной 8-и битным двоичным кодом. Итак, дорогие мои друзья, запомните пожалуйста (если кто не знал):
8 бит = 1 байт.

Так принято. Хотя символ, записанный 2-х или 32-х битным значением так же номинально можно назвать байтом. Кстати, благодаря двоичному коду мы можем оценивать объемы файлов, измеряемые в байтах и скорость передачи информации и интернета (бит в секунду).
Бинарная кодировка в действии
Для стандартизации записи информации для компьютеров было разработано несколько кодировочных систем, одна из которых ASCII, базирующаяся на 8-и битной записи, получила широкое распространение. Значения в ней распределены особым образом:
- первый 31 символ – управляющие (с 00000000 по 00011111). Служат для служебных команд, вывода на принтер или экран, звуковых сигналов, форматирования текста;
- следующие с 32 по 127 (00100000 – 01111111) латинский алфавит и вспомогательные символы и знаки препинания;
- остальные, до 255-го (10000000 – 11111111) – альтернативная, часть таблицы для специальных задач и отображения национальных алфавитов;
Расшифровка значений в ней показано в таблице.

Если вы считаете, что «0» и «1» расположены в хаотичном порядке, то глубоко ошибаетесь. На примере любого числа я вам покажу закономерность и научу читать цифры, записанные двоичным кодом. Но для этого примем некоторые условности:
- Байт из 8 знаков будем читать справа налево;
- Если в обычных числах у нас используются разряды единиц, десятков, сотен, то здесь (читая в обратном порядке) для каждого бита представлены различные степени «двойки»: 256-124-64-32-16-8- 4-2-1;
- Теперь смотрим на двоичный код числа, например 00011011. Там, где в соответствующей позиции есть сигнал «1» – берем значения этого разряда и суммируем их привычным способом. Соответственно: 0+0+0+32+16+0+2+1 = 51. В правильности данного метода вы можете убедиться, взглянув на таблицу кодов.

Теперь, мои любознательные друзья, вы не только знаете что такое двоичный код, но и умеете преобразовать зашифрованную им информацию.
Язык, понятный современной технике
Конечно, алгоритм считывания двоичного кода процессорными устройствами намного сложнее. Но зато его помощью можно записать все что угодно:
- Текстовую информацию с параметрами форматирования;
- Числа и любые операции с ними;
- Графические и видео изображения;
- Звуки, в том числе и выходящие и за предел нашей слышимости;
Помимо этого, благодаря простоте «изложения» возможны различные способы записи бинарной информации:
Дополняет преимущества двоичного кодирования практически неограниченные возможности по передаче информации на любые расстояния. Именно такой способ связи используется с космическими кораблями и искусственными спутниками.
Так что, сегодня двоичная система счисления является языком, понятным большинству используемых нами электронных устройств. И что самое интересное, никакой другой альтернативы для него пока не предвидится.

Думаю, что изложенной мною информации для начала вам будет вполне достаточно. А дальше, если возникнет такая потребность, каждый сможет углубиться в самостоятельное изучение этой темы.
Я же буду прощаться и после небольшого перерыва подготовлю для вас новую статью моего блога, на какую-нибудь интересную тему.
Лучше, если вы сами ее мне подскажите;)
До скорых встреч.